

















![“[Building nerf blasters] became this outlet of creativity for me that hasn't been matched by anything else. The process [of] making a build complete to your desire is such a painstakingly difficult process, but I've had to learn from [the skills needed from] soldering to proper painting. There's so many different options for everything, if you think about it, it exists. The best part is [that] if it doesn't exist, you can build it yourself," Ishaan Parate said.](https://harkeraquila.com/wp-content/uploads/2022/08/DSC_8149-900x604.jpg)




![“When I came into high school, I was ready to be a follower. But DECA was a game changer for me. It helped me overcome my fear of public speaking, and it's played such a major role in who I've become today. To be able to successfully lead a chapter of 150 students, an officer team and be one of the upperclassmen I once really admired is something I'm [really] proud of,” Anvitha Tummala ('21) said.](https://harkeraquila.com/wp-content/uploads/2021/07/Screen-Shot-2021-07-25-at-9.50.05-AM-900x594.png)







![“I think getting up in the morning and having a sense of purpose [is exciting]. I think without a certain amount of drive, life is kind of obsolete and mundane, and I think having that every single day is what makes each day unique and kind of makes life exciting,” Neymika Jain (12) said.](https://harkeraquila.com/wp-content/uploads/2017/06/Screen-Shot-2017-06-03-at-4.54.16-PM.png)






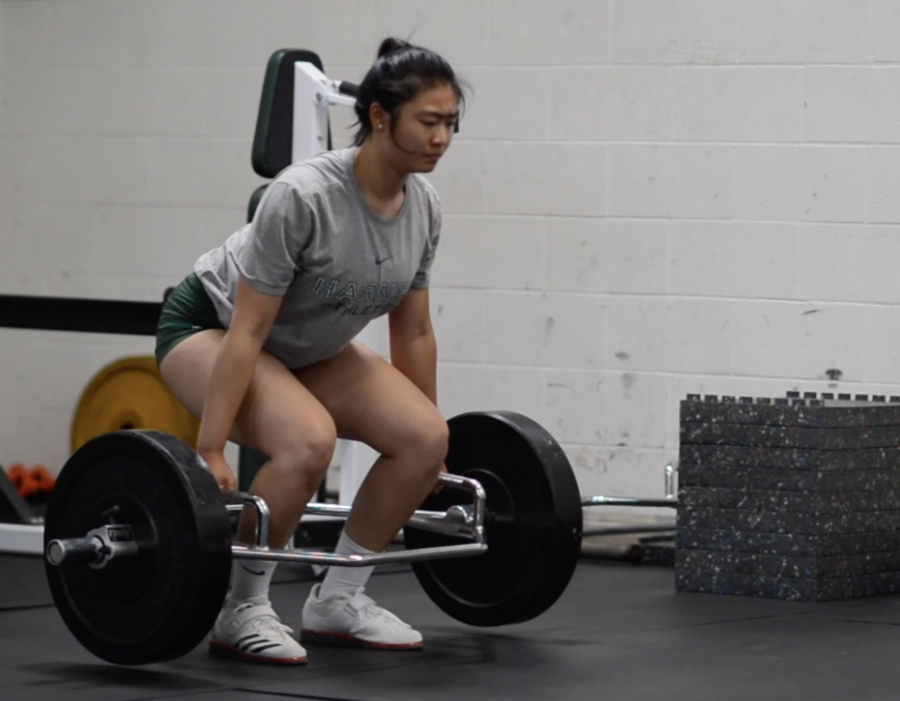

![“My slogan is ‘slow feet, don’t eat, and I’m hungry.’ You need to run fast to get where you are–you aren't going to get those championships if you aren't fast,” Angel Cervantes (12) said. “I want to do well in school on my tests and in track and win championships for my team. I live by that, [and] I can do that anywhere: in the classroom or on the field.”](https://harkeraquila.com/wp-content/uploads/2018/06/DSC5146-900x601.jpg)
![“[Volleyball has] taught me how to fall correctly, and another thing it taught is that you don’t have to be the best at something to be good at it. If you just hit the ball in a smart way, then it still scores points and you’re good at it. You could be a background player and still make a much bigger impact on the team than you would think,” Anya Gert (’20) said.](https://harkeraquila.com/wp-content/uploads/2020/06/AnnaGert_JinTuan_HoHPhotoEdited-600x900.jpeg)

![“I'm not nearly there yet, but [my confidence has] definitely been getting better since I was pretty shy and timid coming into Harker my freshman year. I know that there's a lot of people that are really confident in what they do, and I really admire them. Everyone's so driven and that has really pushed me to kind of try to find my own place in high school and be more confident,” Alyssa Huang (’20) said.](https://harkeraquila.com/wp-content/uploads/2020/06/AlyssaHuang_EmilyChen_HoHPhoto-900x749.jpeg)



“Hey Figure 01, what do you see right now?”
“I see a red apple on a plate in the center of the table, a drying rack with cups and a plate and you standing nearby with your hand on the table.”
Visual processing and answering image-based questions are only some of the many features of Figure 01, robotics firm Figure’s and artificial intelligence organization OpenAI’s newest robot. Trained with text-to-speech models from ChatGPT, Figure 01 is the first autonomous humanoid that holds advanced speech abilities and engages in real-time conversation with humans.
Figure 01 stands at the forefront of innovation, showcasing a level of sophistication unseen in previous humanoids. It incorporates a Vision-Language Model (VLM), an advanced AI application capable of processing both text and images, and its cameras are equipped with highly precise image calibrations.
“These robots just take in whatever we are teaching them through machine learning algorithms,” computer science teacher Swati Mittal said. “We give them so much information. The data is the key for them: they’re learning through the data, and once they have enough data to process themselves, they start learning by themselves as well.”
Figure 01 speaks in a natural, human-like manner and articulates its thought process through a text-to-speech model. Leveraging stored information, Figure 01 makes inferences rapidly, similar to OpenAI’s GPT-3 and GPT-4.
Many people have even pointed out that Figure 01 occasionally stutters and uses filler words like “uh” and “um.” On the OpenAI Developer Forum, a site where users can ask questions and communicate with other developers, some people claim that these filler words make the robot’s speech appear staged, while others believe that it reinforces Figure 01’s human-like qualities.
Clad in silver, weighing 60 kilograms and standing at a height of 5 feet and 6 inches, Figure 01 is designed to replicate the physical characteristics of a human, like a fully functional replica of a human hand with five fingers and moveable joints. This design choice is based on Figure’s belief that “the potential of our future lies in the human form.”
Figure’s primary hope for its technology is to address the shrinking labor force. By utilizing a robot that closely resembles a person, the company aims to potentially reduce the time that humans spend on tedious tasks in the workforce. Programming Club president Joe Li (12) predicts that Figure 01 will fulfill the company’s goals, but that it will also bring negative impacts, like job layoffs, once implemented.
“With artificial general intelligence, there are a lot of positive impacts like benefitting labor shortages in areas like nursing,” Joe said. “During COVID, there was a shortage of nurses and doctors. Figure 01 addresses the need for these human workers and can replace them with the robot. On the other hand, though, it’s going to take away a lot of jobs. That’s unfortunate, but as technology develops, it’s just something that’s inevitably going to happen.”
Figure further showcased Figure 01’s complex abilities in a demonstration posted on X on March 13. After the demonstrator said that he wanted something to eat, the robot identified an apple as an edible item among other items on the table, like dishes, cups and a drying rack. It went even further and placed the apple in the demonstrator’s hand and explained its reasoning: “I gave you the apple because it’s the only, uh, edible item I could provide you with from the table.”
Despite its fairly recent start in 2022, Figure has attracted substantial interest from investors like Nvidia and Microsoft. Figure 01 has even partnered with BMW Manufacturing to integrate its robots into the difficult, dangerous aspects of the car manufacturing process like inside the warehouse or body shop.
However, many people doubt that Figure 01 will be a viable product due to its concerningly rapid development in AI and robotic systems. Robotics team member Arturo Vilalta (10) argues that the full extent of Figure 01’s impact is yet to be determined.
“Figure builds upon decades of work in robotic dexterity, computer vision and spatial mapping, but it’s hard to tell if there is anything truly groundbreaking with their work,” Arturo said. “It’s hard to say from the little information available what’s most impressive about the bot because we don’t know much about the technology they are using behind the scenes.”







